Data Lake Warehouse
A cloud-native platform built on OneLake as the unified storage
foundation and based on the open Delta Lake format. It integrates the
flexibility of the data lake with the management capabilities of the
data warehouse, supports ACID transaction processing for structured and
unstructured data, improves data quality through automatic table
discovery and the gold medal system hierarchical architecture, has
built-in Microsoft Purview governance tools, and seamlessly integrates
with Power BI, Azure Synapse Analytics, and Azure OpenAI services to
provide an end-to-end experience from data ingestion to real-time
analysis and AI-driven insights.
Shortcuts
Through the virtual mounting technology of the OneLake unified data lake,
achieve seamless access and real-time synchronization of data across
domains, clouds, and storage systems (such as Azure Blob, S3, Google
Cloud Storage). Combined with AI-driven quick actions (such as Copilot
automatically explaining/correcting queries) and seamless switching
across service modules, significantly improve the efficiency and
flexibility of data analysis.
Data Pipeline
Through more than 180 connectors and AI-driven low-code design, achieve
automated integration of multi-source heterogeneous data, mixed
orchestration of real-time and batch processing. Combined with the Fast
Copy technology and OneLake unified storage, it supports efficient flow
and elastic expansion of PB-level data. At the same time, relying on
Copilot intelligent optimization and full-link monitoring and diagnosis,
it provides end-to-end data integration and governance capabilities.
Version Management
Supports end-to-end automated CI/CD processes, seamlessly integrates
with Azure DevOps and Git version control. Through visual orchestration
and multi-environment management (development/testing/production), it
achieves efficient management and control of the content lifecycle. At
the same time, it uses REST APIs and deployment rules to ensure the
consistency and reliability of content across stages.
Notebooks
Deeply integrates Python, T-SQL, and Spark SQL, supporting collaborative
operations in the same environment. It can seamlessly access the lake
warehouse and data warehouse, achieving functions such as distributed
computing, cross-language data transfer, and enterprise-level governance
(such as version control, permission control).
Data Lake Warehouse
A cloud-native platform built on OneLake as the unified storage
foundation and based on the open Delta Lake format. It integrates the
flexibility of the data lake with the management capabilities of the
data warehouse, supports ACID transaction processing for structured and
unstructured data, improves data quality through automatic table
discovery and the Medallion hierarchical architecture, has built-in
Microsoft Purview governance tools, and seamlessly integrates with Power
BI, Synapse Analytics, and Azure AI services to provide an end-to-end
experience from data ingestion to real-time analysis and AI-driven
insights.
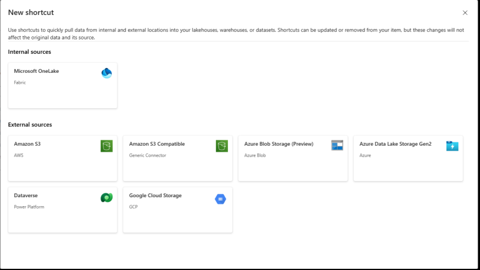
Shortcuts
Through the virtual mounting technology of the OneLake unified data lake,
achieve seamless access and real-time synchronization of data across
domains, clouds, and storage systems (such as Azure Blob, S3, Google
Cloud Storage). Combined with AI-driven quick actions (such as Copilot
automatically explaining/correcting queries) and seamless switching
across service modules, significantly improve the efficiency and
flexibility of data analysis.
Data Pipeline
Through more than 180 connectors and AI-driven low-code design, achieve
automated integration of multi-source heterogeneous data, mixed
orchestration of real-time and batch processing. Combined with the Fast
Copy technology and OneLake unified storage, it supports efficient flow
and elastic expansion of PB-level data. At the same time, relying on
Copilot intelligent optimization and full-link monitoring and diagnosis,
it provides end-to-end data integration and governance capabilities.
Version Management
Supports end-to-end automated CI/CD processes, seamlessly integrates
with Azure DevOps and Git version control. Through visual orchestration
and multi-environment management (development/testing/production), it
achieves efficient management and control of the content lifecycle. At
the same time, it uses REST APIs and deployment rules to ensure the
consistency and reliability of content across stages.
Notebooks
Deeply integrates Python, T-SQL, and Spark SQL, supporting collaborative
operations in the same environment. It can seamlessly access the lake
warehouse and data warehouse, achieving functions such as distributed
computing, cross-language data transfer, and enterprise-level governance
(such as version control, permission control).